
Zastosowanie mechanizmu ewolucji biologicznej do znajdowania parametrów w modelach statystycznych

Zastosowanie mechanizmu ewolucji biologicznej do znajdowania parametrów w modelach statystycznych – małe wyzwanie, pod kątem kodowania i myślenia o teorii, w sam raz na weekend ![]()
Przykład: im starszy las, tym więcej ptaków (to na ogół prawda, m.in. dlatego chcemy chronić stare lasy), i taką zależność można opisać konkretnym parametrem nachylenia linii regresji, który wyjaśnia o ile zmieni się liczba ptaków, gdy wiek lasu zwiększy się o rok. Np. z każdym rokiem wieku lasu przybywa ćwierć gatunku ptaka. To „ćwierć”, to właśnie nachylenie regresji. Mając dane o wieku lasu i liczbie ptaków z różnych miejsc możemy szybko ten parametr znaleźć (robi to za nas komputer) dopasowując optymalne nachylenie linii (bez wchodzenia w szczegóły: takie, które najlepiej wyjaśni zależność).
To samo zadanie (znalezienie parametru) można jednak wykonać inaczej – stosując wirtualną ewolucję. Ja zrobiłem to tak: generuję 300 wirtualnych lasów o różnym wieku, dla każdego z nich wyliczam liczbę ptaków wg wzoru: ptaki = 0.1837 * wiek lasu (dla uproszczenia pomijam intercept). Zatem 0.1837 to parametr, którego następnie szukam i w dalszych krokach udaję, że go nie znam.
Zaczynając poszukiwania generuję małą „populację” 5 parametrów jako liczby losowe z rozkładu normalnego ze średnią zero i bardzo dużym rozrzutem. W efekcie dostaję 5 różnych liczb, np. od -100 do 100. Duży rozrzut jest potrzebny, bo poszukiwany parametr jest faktycznie nieznany, nie wiadomo nawet, czy jest dodatni, czy ujemny, rozsądnie jest zatem testować bardzo różne liczby. Każdą z tych 5 wartości podstawiam następnie do równania regresji y = ax (liczba ptaków = parametr * wiek lasu) i sprawdzam, który z tych 5 generuje dane najbardziej zbliżone do rzeczywistych (przypomnę: rzeczywiste znam, bo sam je wygenerowałem). Następnie wybieram najlepszy z całej piątki, a 4 pozostałe odrzucam (sorry, słabsi giną). Ten najlepszy jest następnie „rozmnażany” i ma piątkę „potomstwa” (liczby losowe z rozkładu normalnego o średniej już nie zero, lecz równej najlepszemu parametrowi z poprzedniego kroku), które to „potomstwo” znowu konkuruje między sobą o bycie najlepszym, najlepszy z nich jest rozmnażany, itd. Podczas generowania liczb losowych dopuszczony rozrzut w kolejnych iteracjach stopniowo się zmniejsza, bo chcę by „potomstwo” było zbliżone do „rodziców” (tj. nie chcę by ciągle wariowało od -100 do 100) .
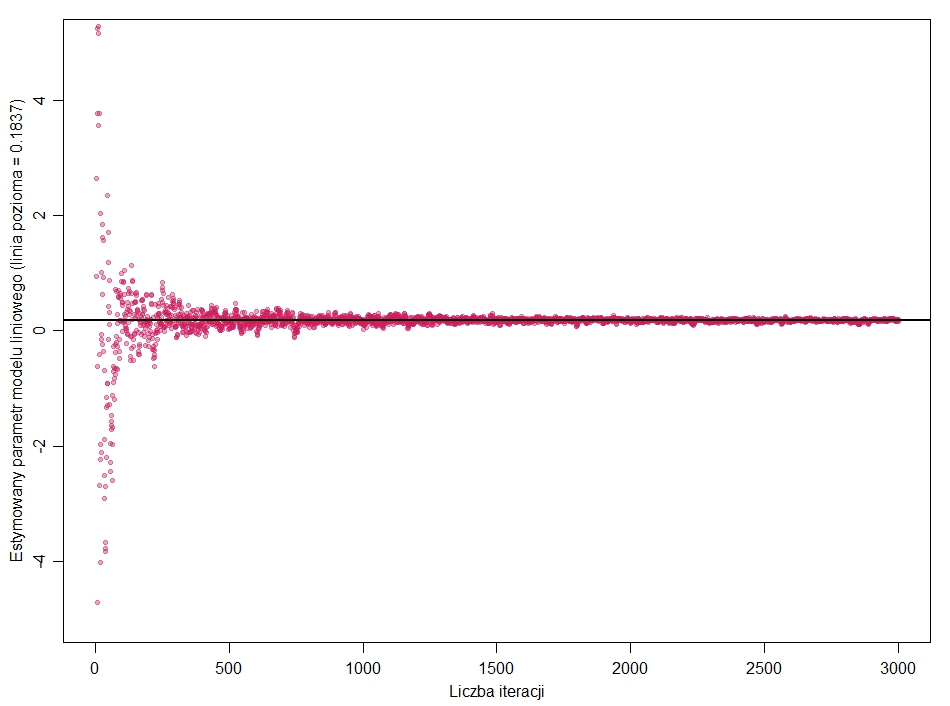
Taka „hodowla” parametrów, startująca od zróżnicowania na poziomie -100;+100, po kilkuset „pokoleniach” generuje populację parametrów bardzo zbliżonych do rzeczywistego, zawierającą się w przedziale mniej więcej 0.15 do 0.20; ze średnią 0.1829 (przypomnę, prawdziwy to 0.1837). Kolejne kilka tysięcy iteracji zawęża zmienność do przedziału 0.178; 0.186. Zatem praktycznie znaleźliśmy szukany parametr bez użycia wzorów, bazując wyłącznie na mechanizmach ewolucyjnych i komputerowych symulacjach. Ewolucja działa, również tu! Rycina obrazuje parametry wyhodowane w kolejnych pokoleniach (iteracje).
Wpis ukazał się pierwotnie na facebooku prof. Michała Żmihorskiego tutaj. Posty z fb nie są recenzowane, stanowią swego rodzaju archiwum informacji z ulotnego środowiska mediów społecznościowych.
Dr hab. Michał Żmihorski. prof. IBS PAN, dyrektor Instytutu Biologii Ssaków Polskiej Akademii Nauk.
