
Wielkanocne poszukiwania najkrótszej trasy przejazdu

Tej wiosny mam do skontrolowania 15 lokalizacji w Puszczy Białowieskiej (będzie ich więcej, ale na razie wiem o 15). Zacząłem zastanawiać się nad kolejnością ich odwiedzania, by skrócić trasę przejazdu. Każdy z nas robi to intuicyjnie: będąc w jednej części lasu kontroluję wszystkie pobliskie punkty, bym nie musiał potem wracać, a następnie jadę do tych położonych dalej. Jednak w ramach świątecznego odpoczynku spróbowałem skonstruować algorytm do wyszukania optymalnej trasy.
Najpierw wyznaczyłem trasę bez pomocy algorytmów, patrząc na mapę (ignorując dostępność dróg – punkty łączyłem prostymi odcinkami, przyjąłem też, że zaczynam i kończę trasę w punkcie nr 16). Moja trasa miała długość 43,7 km. Potem, licząc na szybki efekt przy niewielkim wysiłku, zacząłem generować losowe sekwencje punktów i dla każdej obliczałem sumaryczną długość trasy w nadziei, że jakaś losowa okaże się lepsza od mojej (tj. krótsza niż 43.7). Niektóre losowe sekwencje generowały trasę wyraźnie krótszą niż inne, ale średnia długość wynosiła ok 100 km, a żadna nie była krótsza niż 50 km (pomarańczowe linie na wykresie, 5000 przykładowych realizacji). Co gorsze, policzyłem, że mając 15 punktów liczba możliwych kombinacji sekwencji odwiedzanych punktów wynosi bilion i trzysta miliardów. Zakładając, że kolejność odwiedzin nie gra roli (np. sekwencja A-B-C oraz C-B-A są dla mnie tożsame) powinniśmy rozpatrzeć połowę: 650 mld unikalnych sekwencji. Przy moim dość mocnym laptopie (64GBRAM) policzenie dystansu dla wszystkich kombinacji zajęłoby 116 lat ciągłej pracy.
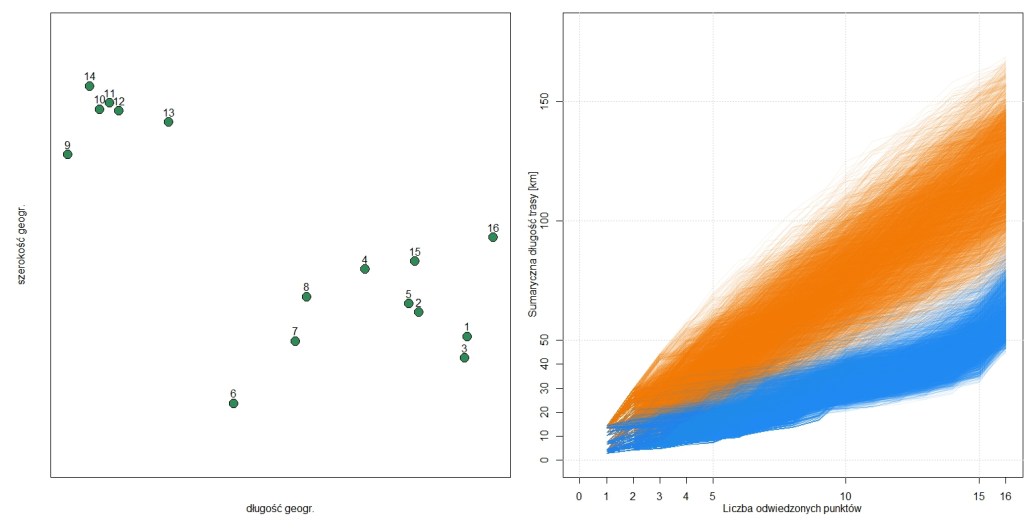
Drugie podejście polegało na dołożeniu do losowania sekwencji wagi odwrotnie proporcjonalnej do dystansu między punktami, by punkty położone blisko siebie były częściej losowane po sobie (dla ścisłości: odwrotność dystansu podniosłem jeszcze do czwartej potęgi, by bardziej zmniejszyć częstość losowania dużych odległości) i wykluczyć trasy w oczywisty sposób bezsensowne (skakanie z jednego końca lasu na drugi). I tu poszło lepiej: po 500,000 próbach (ok. 40 minut obliczeń) najkrótsza znaleziona trasa to 42,9 km, więc nieco krótsza od mojej (niebieskie linie na wykresie). Chyba najkrótsza możliwa.
Dwa spostrzeżenia z tego ćwiczenia: zysk jest nieduży (~800m), więc metoda „na oko” jest skuteczna, chociaż przy większej liczbie punktów (albo innym ich ułożeniu) przewaga komputera może rosnąć. Po drugie: nie przychodzi mi do głowy, jak poprawić taki algorytm, by wyjść poza metodę prób i błędów.
Wesołych Świąt!
Wpis ukazał się pierwotnie na facebooku tutaj. Posty z fb nie są recenzowane, stanowią swego rodzaju archiwum informacji z ulotnego środowiska mediów społecznościowych.
Dr hab. Michał Żmihorski. prof. IBS PAN, dyrektor Instytutu Biologii Ssaków Polskiej Akademii Nauk.
